# A tibble: 2 × 2
smoker n
<chr> <int>
1 non-smoker 27
2 smoker 17More data wrangling and data visualization with the tidyverse
remixed from Claus O. Wilke’s SDS375 course
Discussions: discord
Ask questions at #workshop-questions on https://discord.gg/UDAsYTzZE.
Stickies
During an activity, place a yellow sticky on your laptop if you’re good to go and a pink sticky if you want help.
Analyze subsets: group_by() and summarize()

Let’s take a poll
Go to the event on wooclap
What 4 columns do you expect in the output of this code?
Reshape: pivot_wider() and pivot_longer()

We use joins to add columns from one table into another

Joins turn two tables into one

There are different types of joins
The differences are all about how to handle when the two tables have different key values

left_join() - the resulting table always has the same key_values as the “left” table
right_join() - the resulting table always has the same key_values as the “right” table
inner_join() - the resulting table always only keeps the key_values that are in both tables
full_join() - the resulting table always has all key_values found in both tables
Left Join
left_join() - the resulting table always has the same key_values as the “left” table
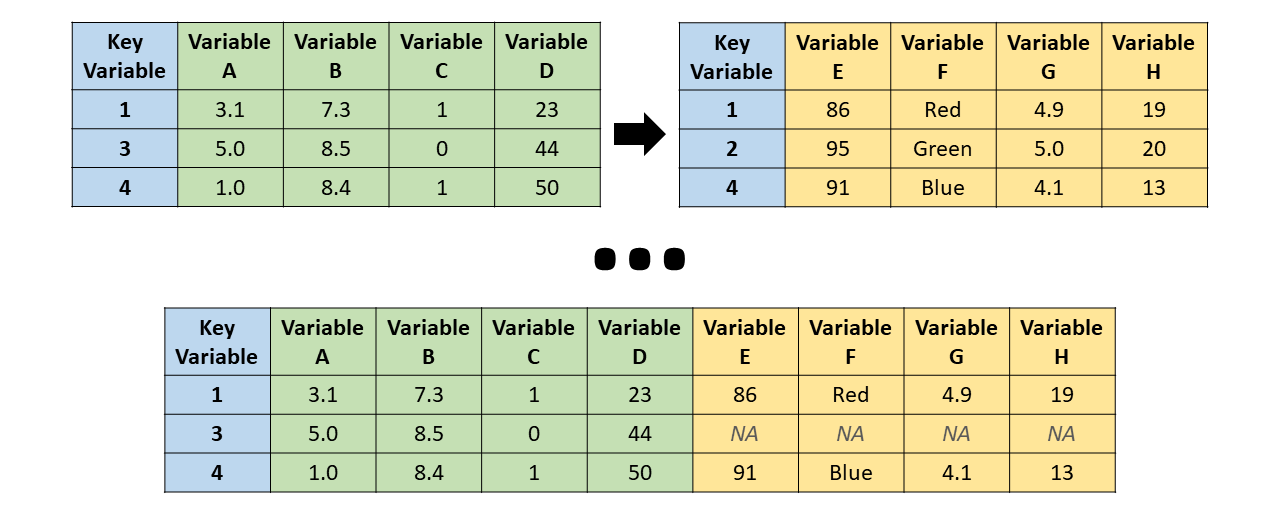
Right Join
right_join() - the resulting table always has the same key_values as the “right” table

inner_join
inner_join() - the resulting table always only keeps the key_values that are in both tables
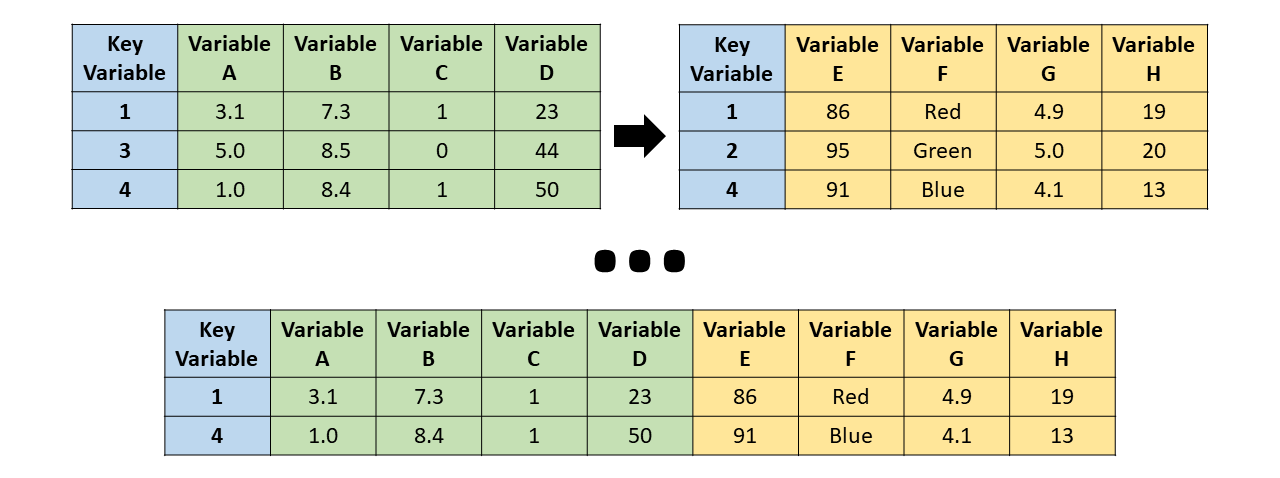
Full join
full_join() - the resulting table always has all key_values found in both tables

But what are those NAs?
In case of doubt, use left_join()

Note, merging tables vertically is bind_rows(), not a join

Define bins and count classes
| age range | count |
|---|---|
| 0–5 | 36 |
| 6–10 | 19 |
| 11–15 | 18 |
| 16–20 | 99 |
| 21–25 | 139 |
| 26–30 | 121 |
| 31–35 | 76 |
| 36–40 | 74 |
| age range | count |
|---|---|
| 41–45 | 54 |
| 46–50 | 50 |
| 51–55 | 26 |
| 56–60 | 22 |
| 61–65 | 16 |
| 66–70 | 3 |
| 71–75 | 3 |
| 76–80 | 0 |
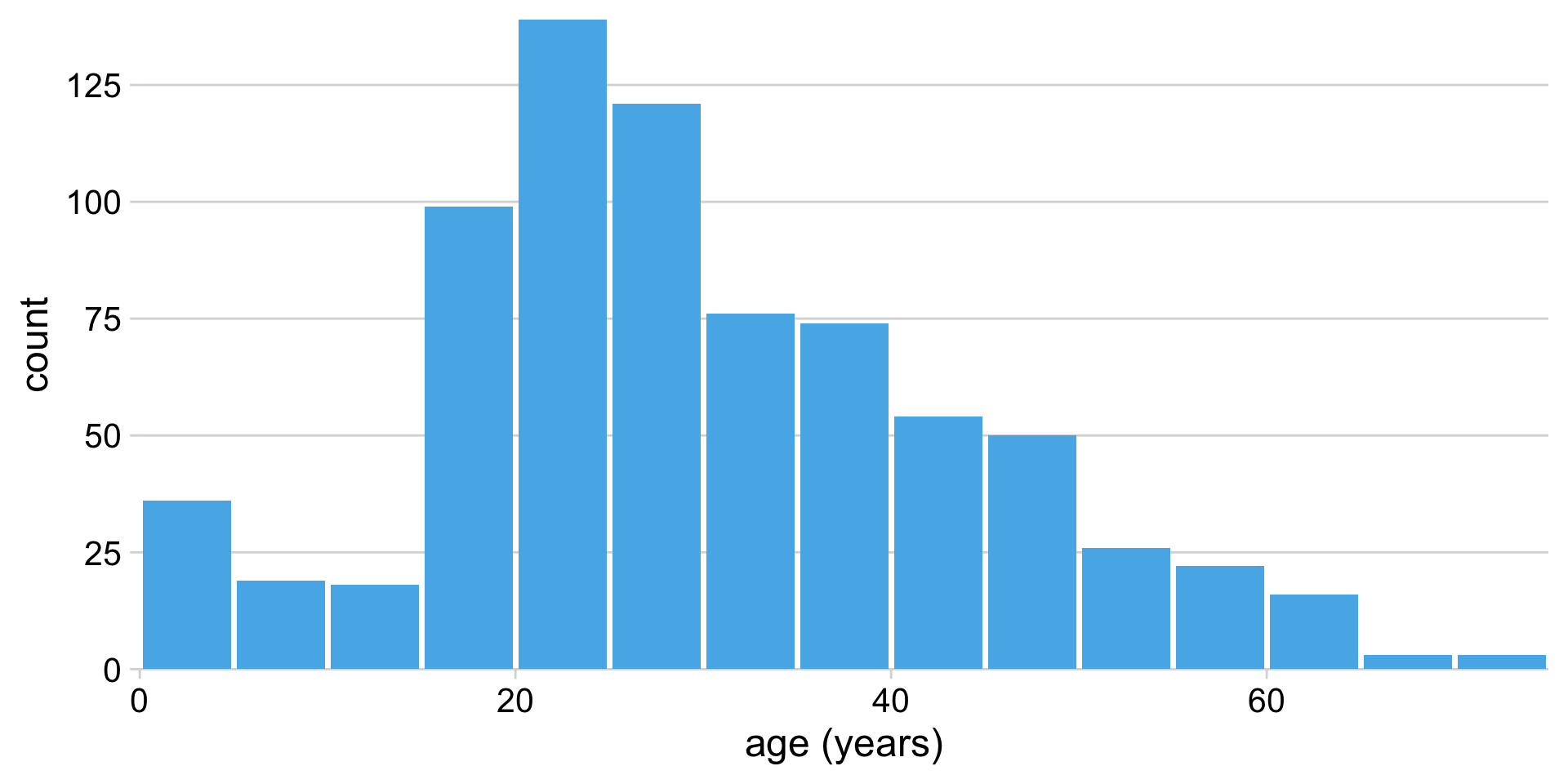
Histograms depend on the chosen bin width

Alternative to histogram: Kernel density estimate (KDE)
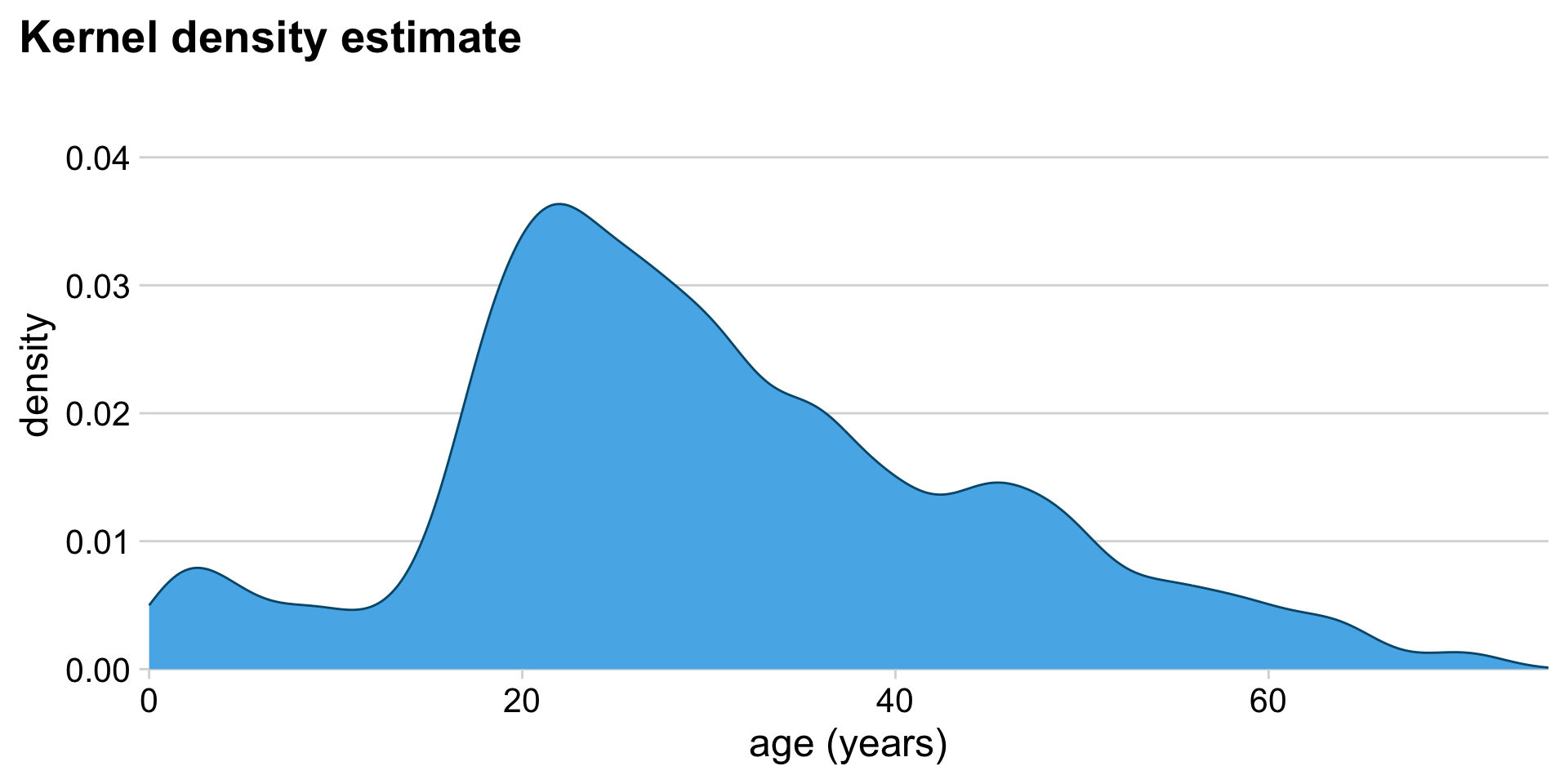
Histograms show raw counts, KDEs show proportions. (Total area = 1)
KDEs also depend on parameter settings

Careful: KDEs can show non-sensical data

Careful, are bars stacked or overlapping?


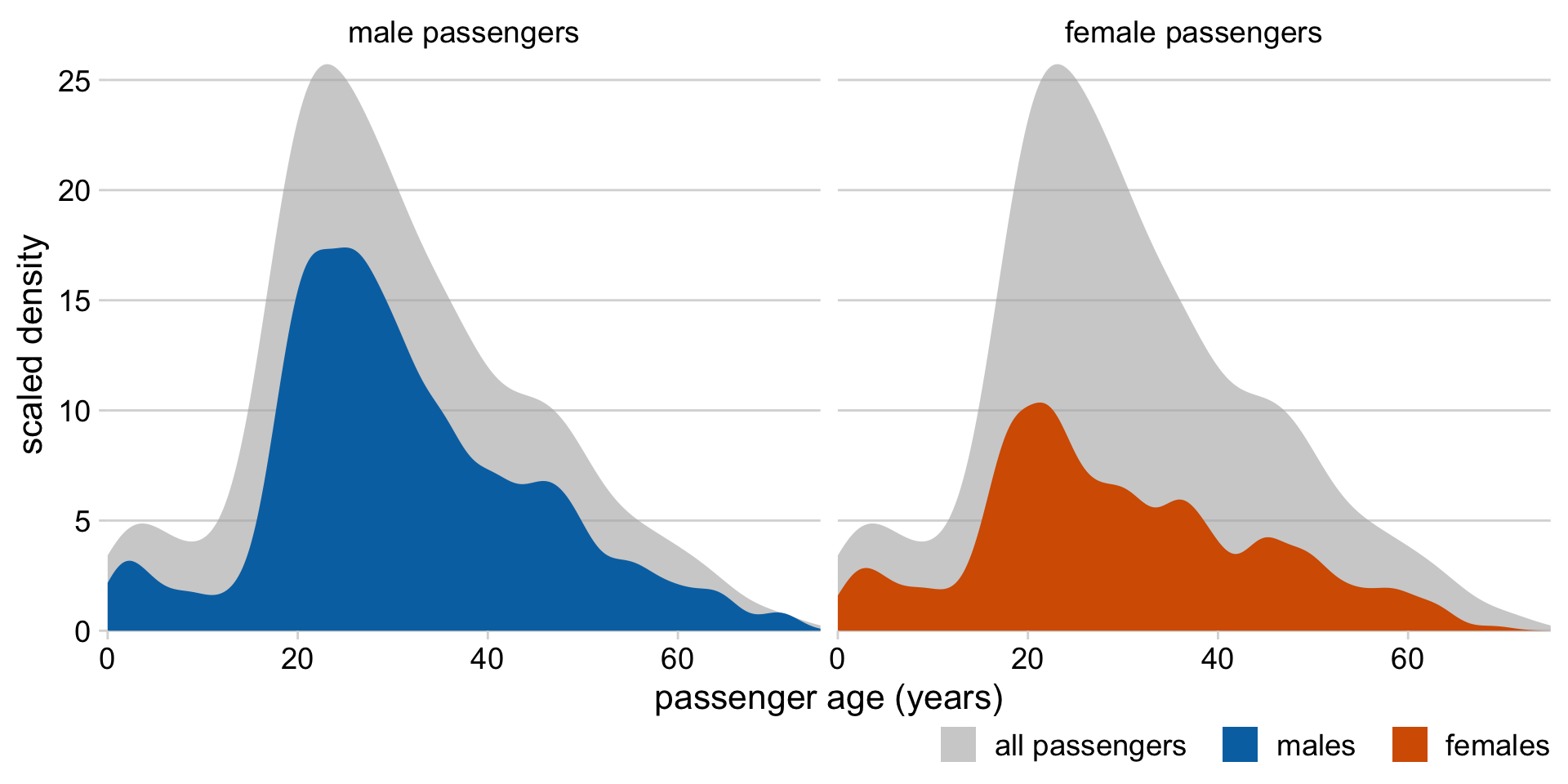
Alternatively: Age pyramid

Alternatively: KDEs showing proportions of total
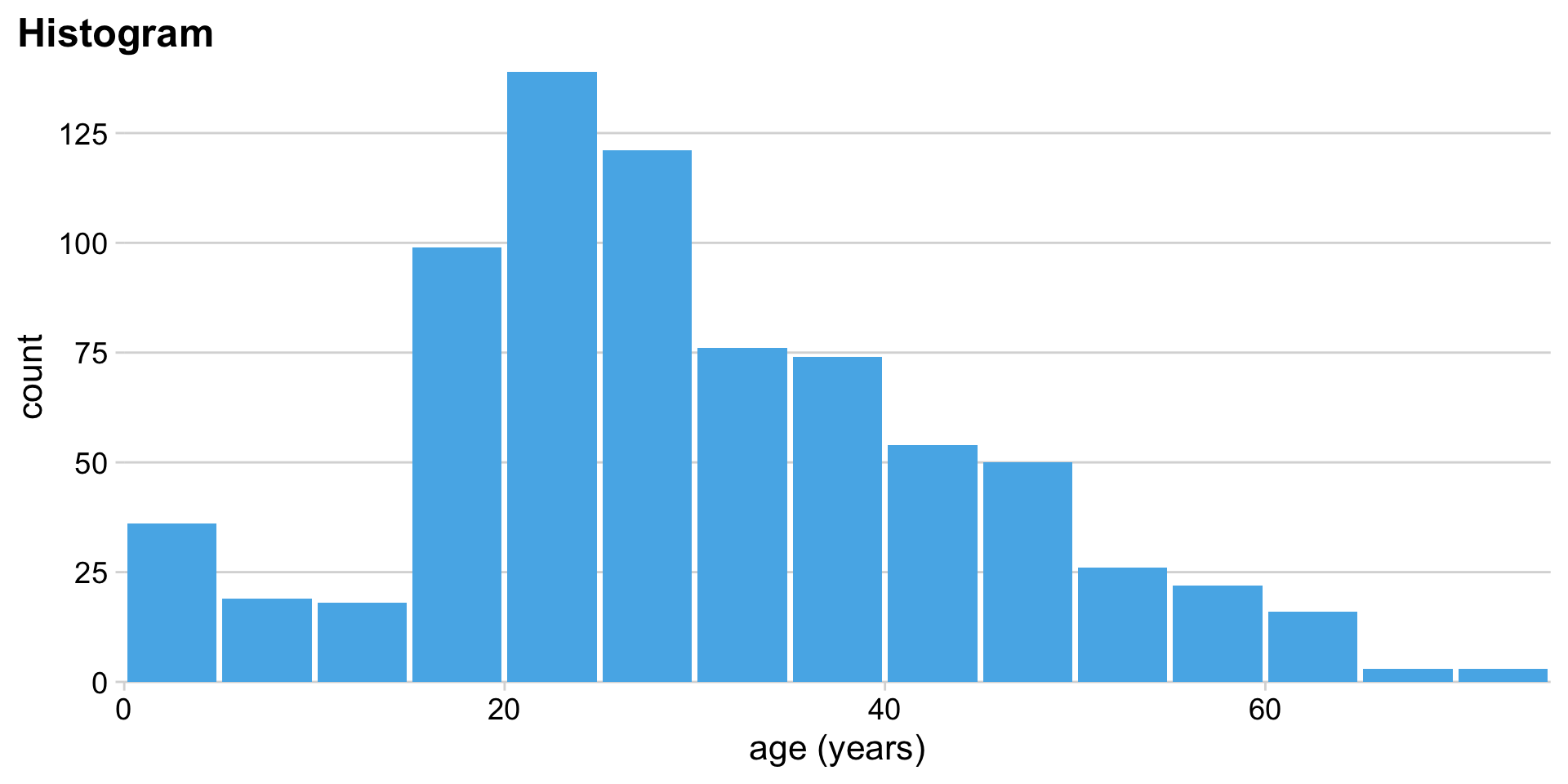
Making histograms with ggplot: geom_histogram()
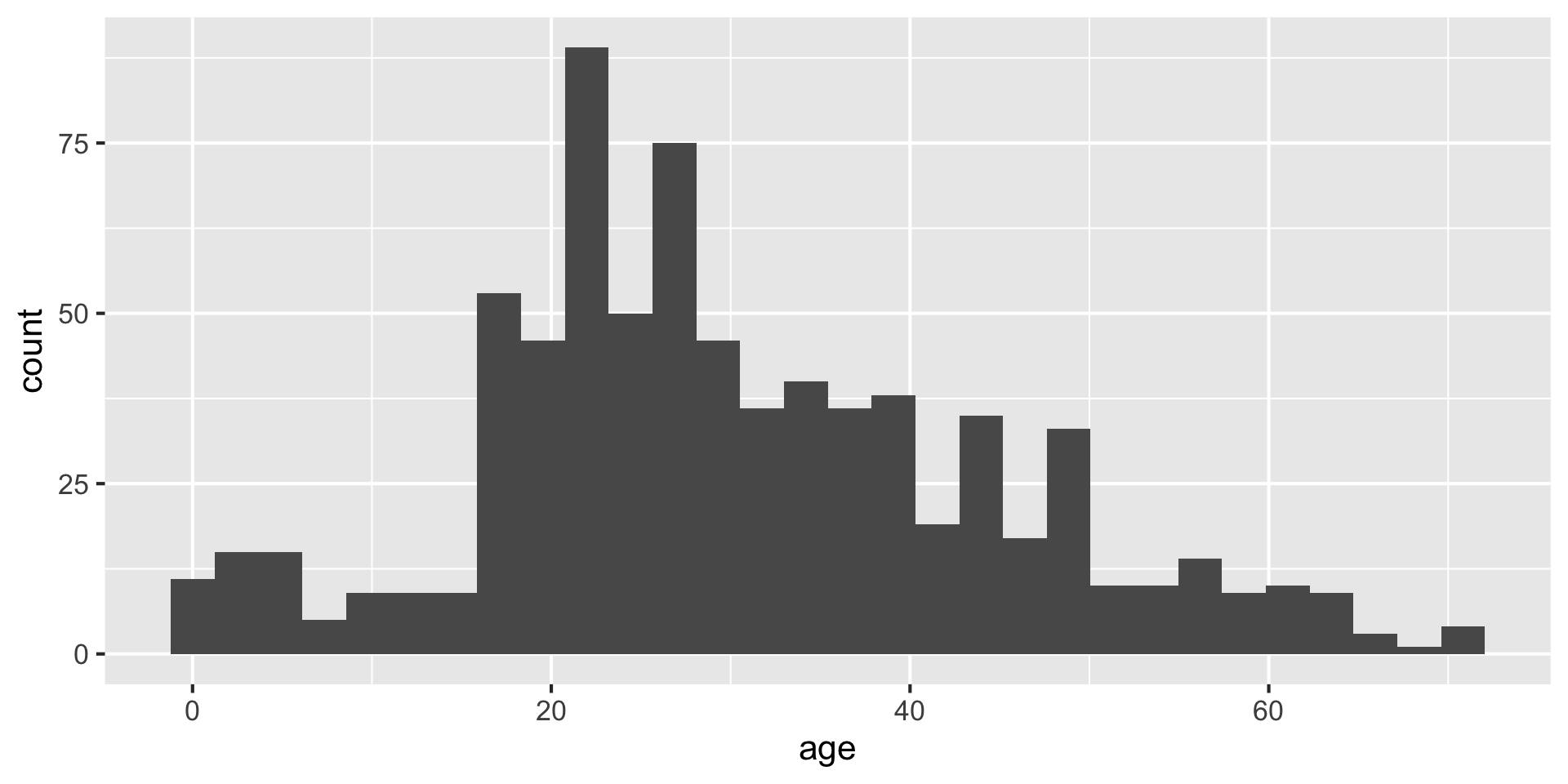
Setting the bin width
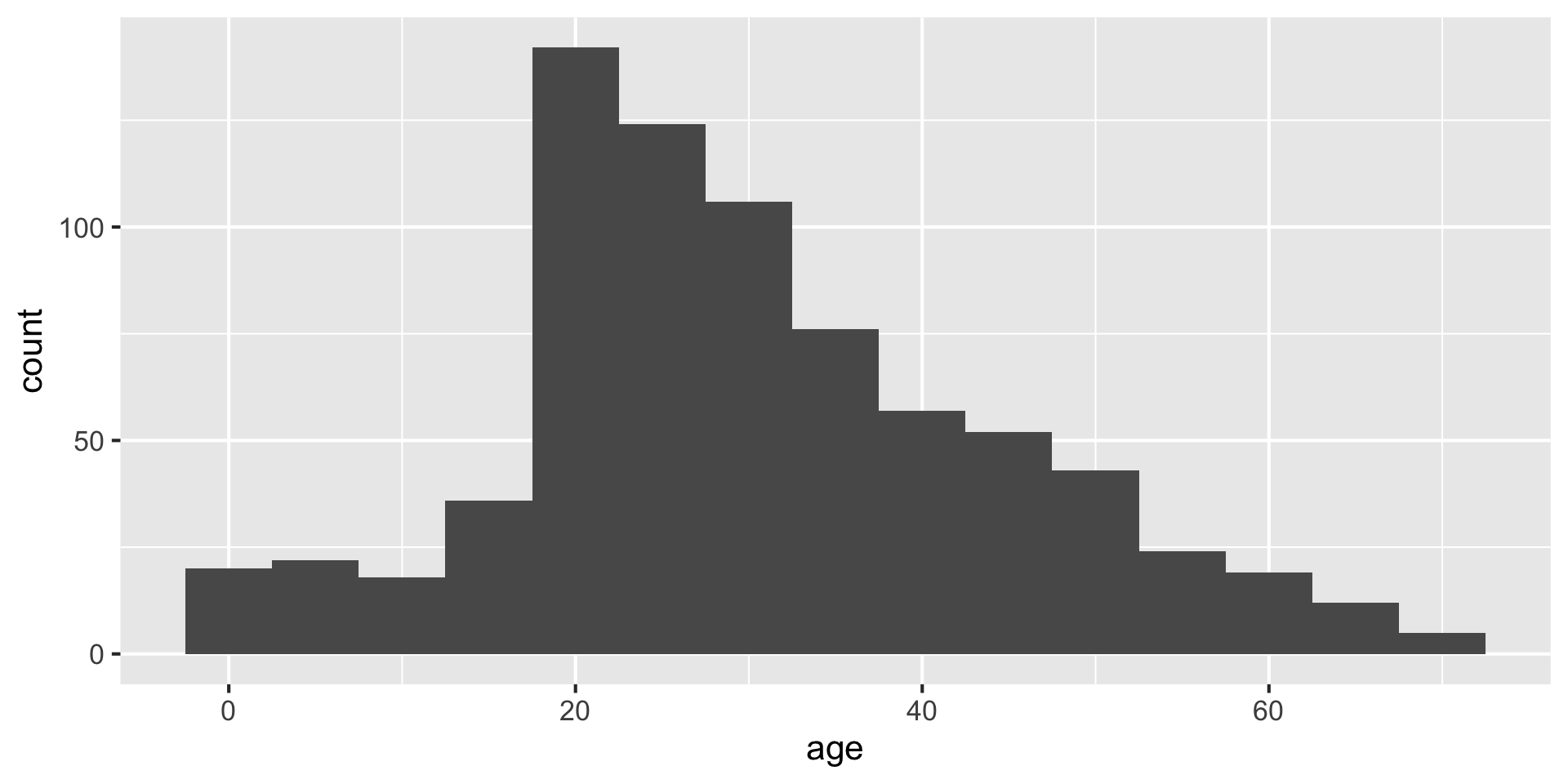
Do you like where there bins are? What does the first bin say?
Always set the center as well, to half the bin_width
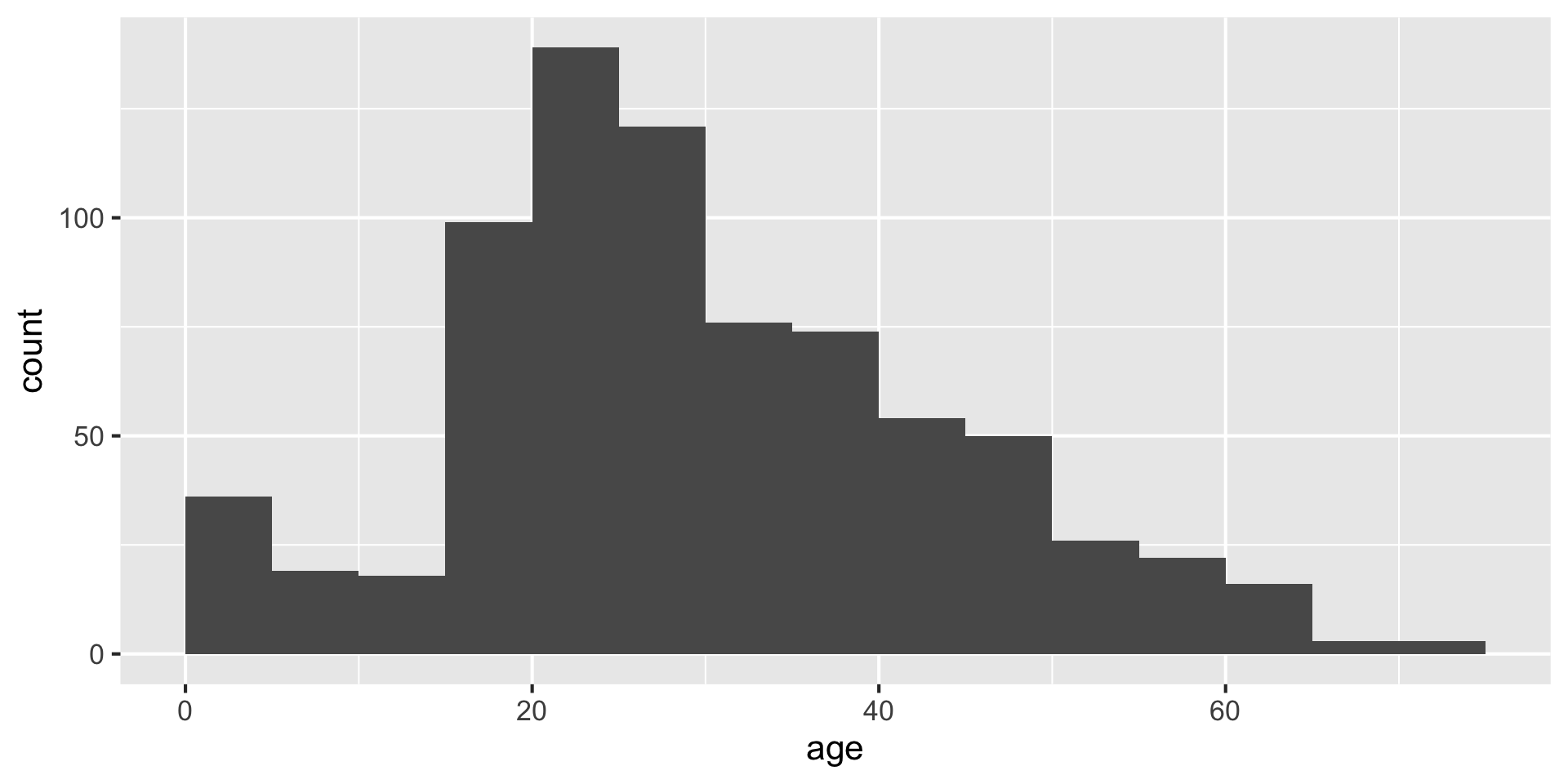
Setting center 2.5 makes the bars start 0-5, 5-10, etc. instead of 2.5-7.5, etc. You could instead use the argument boundary=5 to accomplish the same behavior.
Making density plots with ggplot: geom_density() {auto-animate:true}
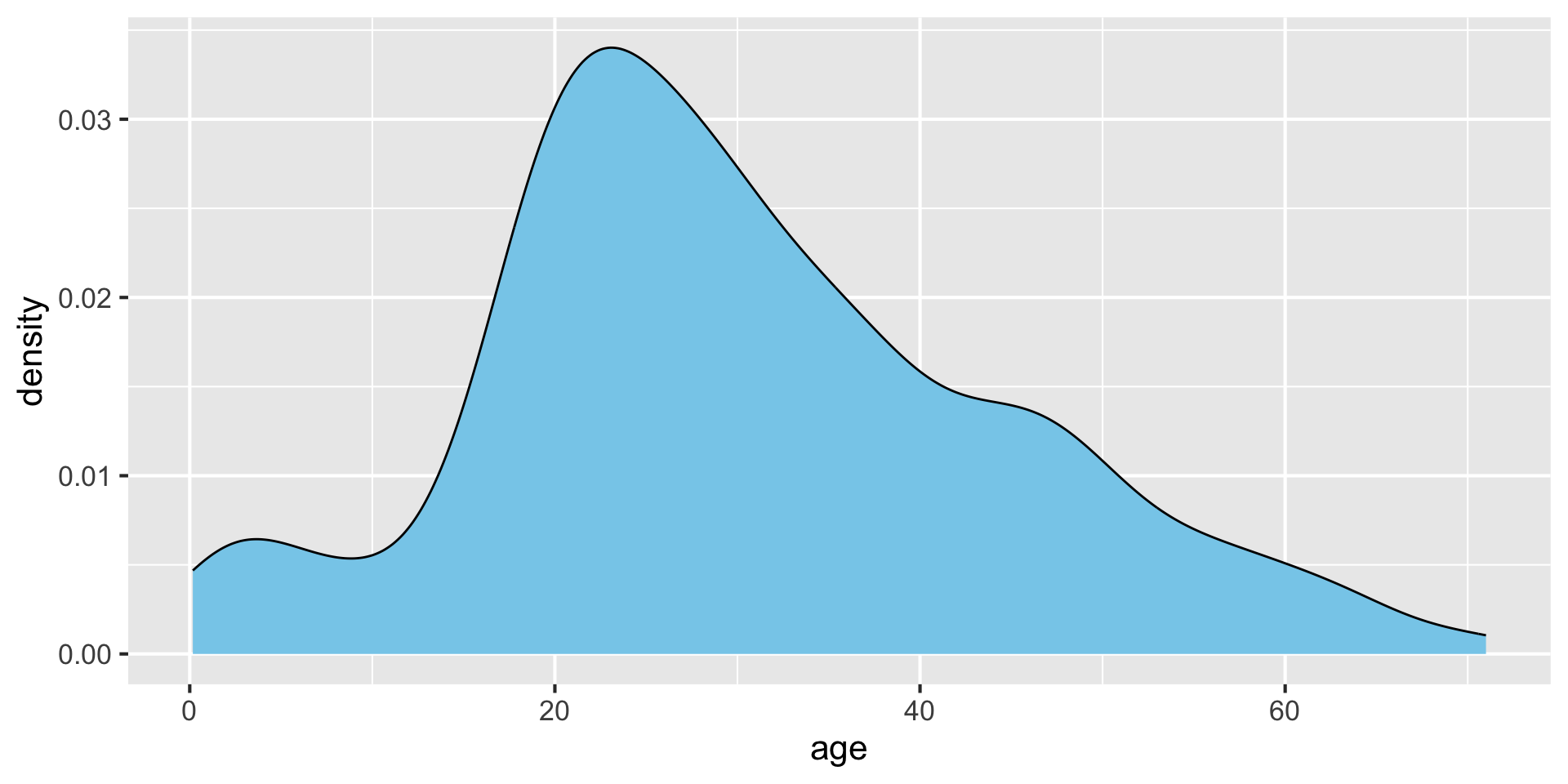
Making density plots with ggplot: geom_density() {auto-animate:true}
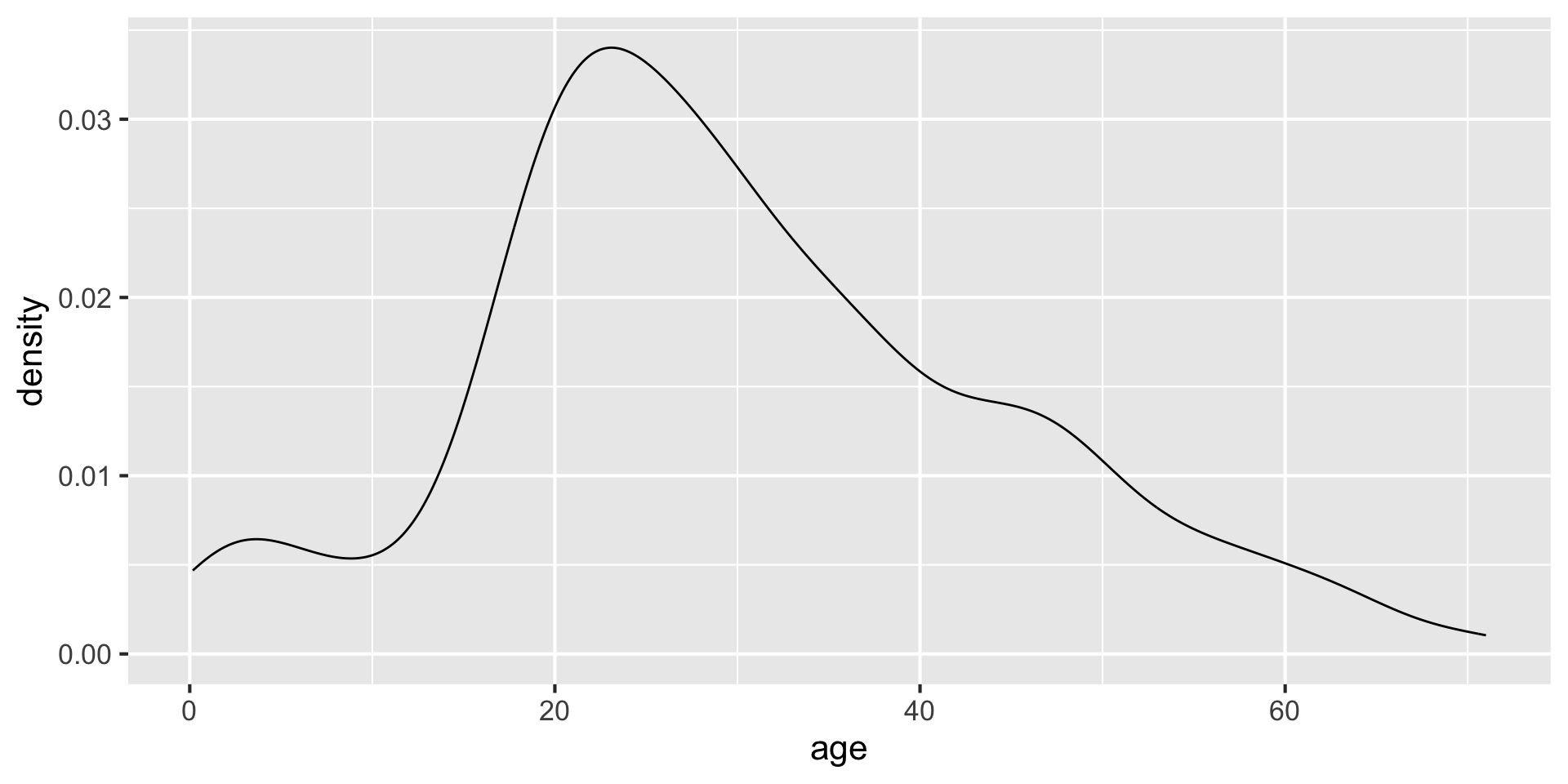
without fill
Modifying bandwidth (bw) and kernel parameters {auto-animate:true}
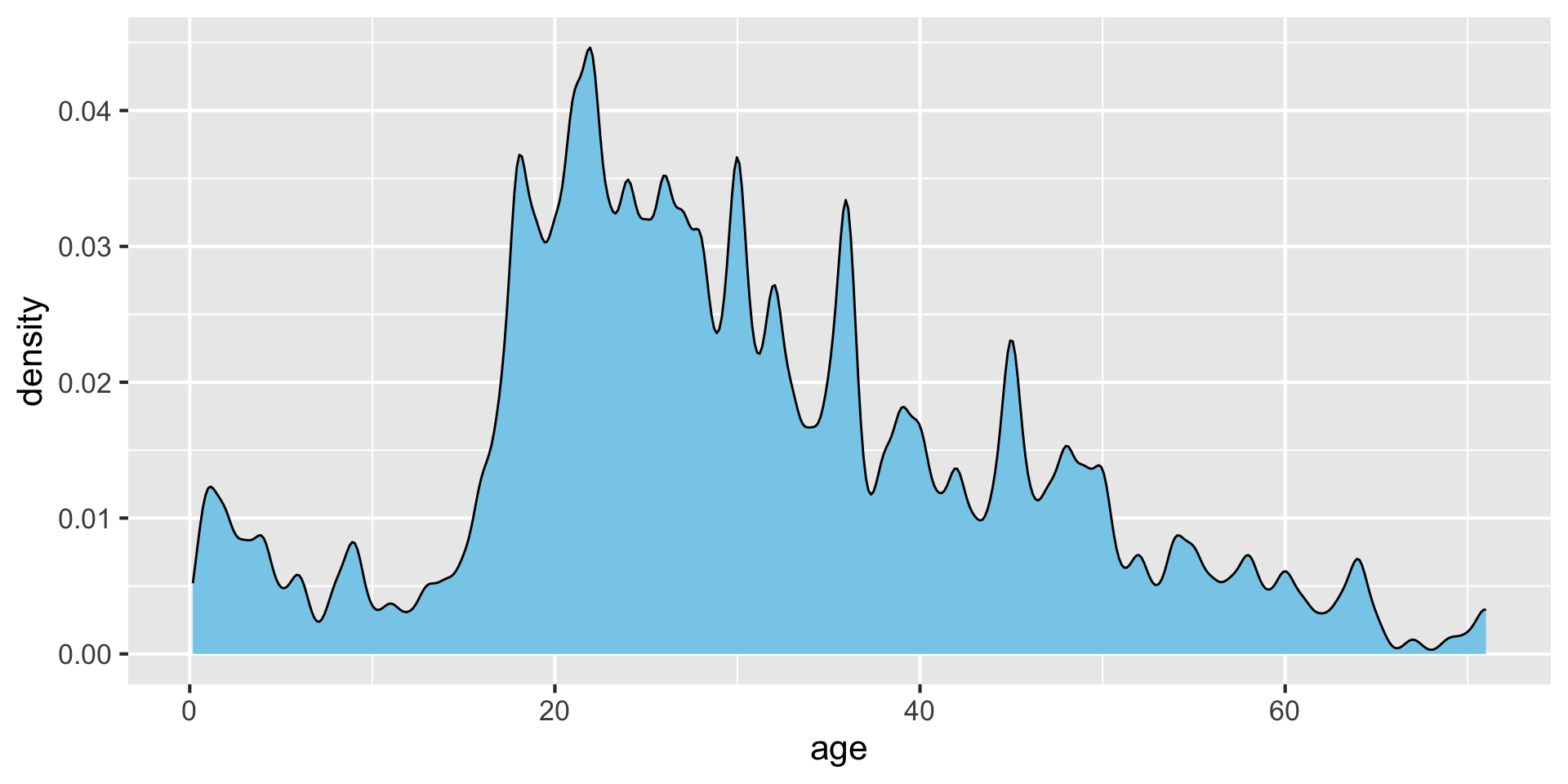
Modifying bandwidth (bw) and kernel parameters {auto-animate:true}
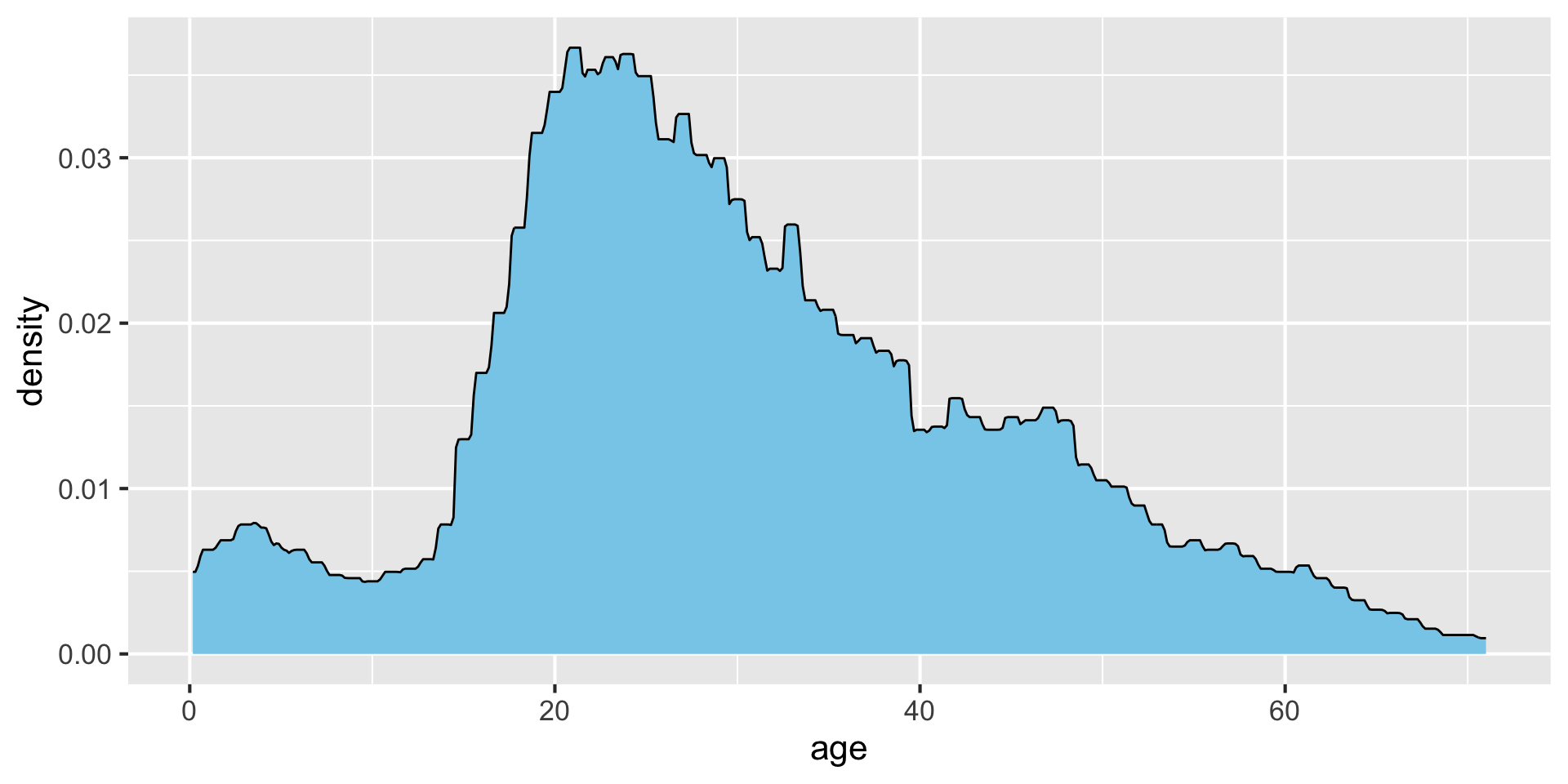
Density estimates visualize distributions
Mean temperatures in Lincoln, NE, in January 2016:
| date | mean temp |
|---|---|
| 2016-01-01 | -4 |
| 2016-01-02 | -5 |
| 2016-01-03 | -5 |
| 2016-01-04 | -8 |
| 2016-01-05 | -2 |
| 2016-01-06 | 1 |
| 2016-01-07 | -1 |
| 2016-01-08 | -4 |
| 2016-01-09 | -13 |
| 2016-01-10 | -12 |
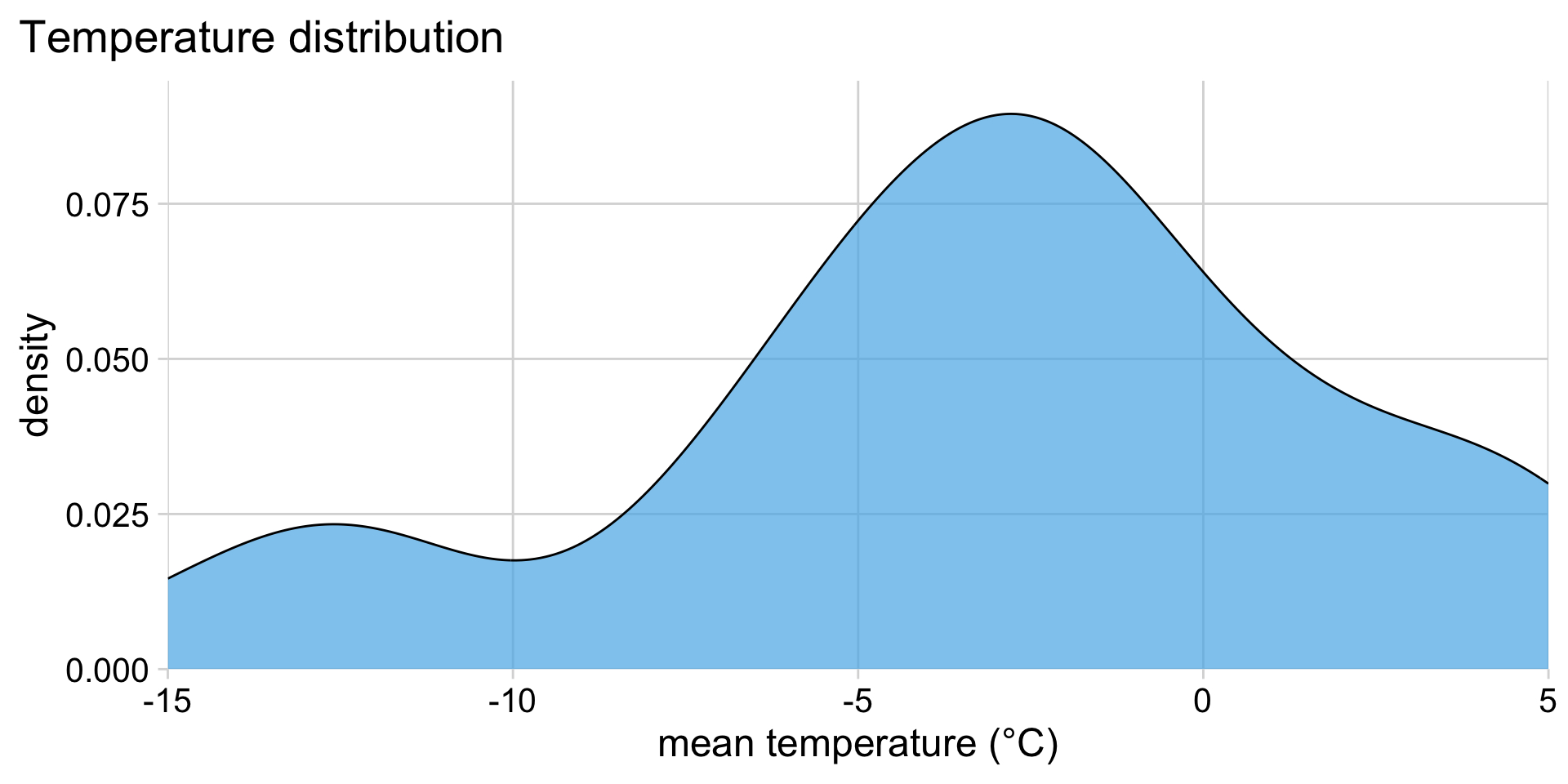
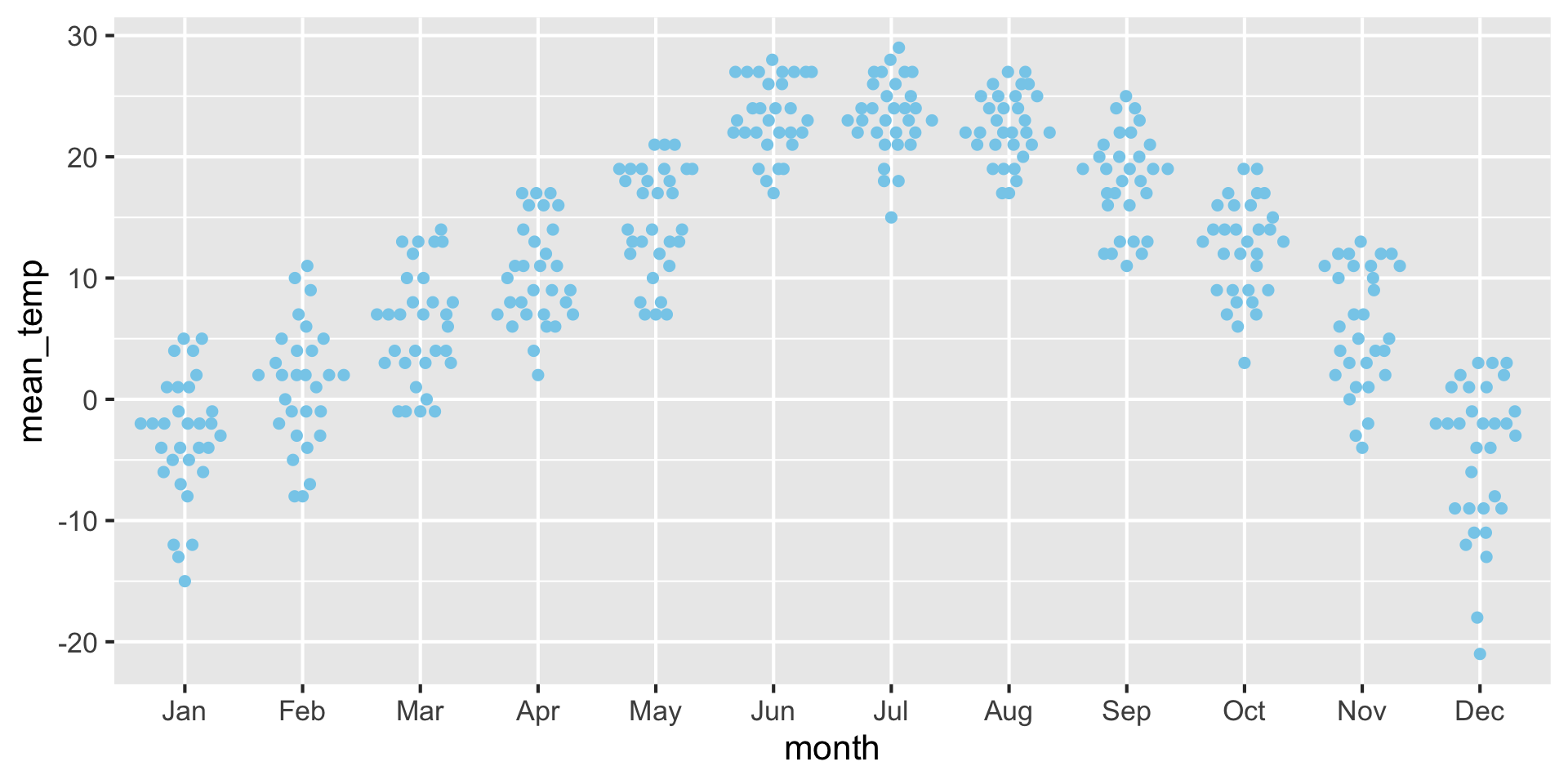
How can we compare distributions across months?
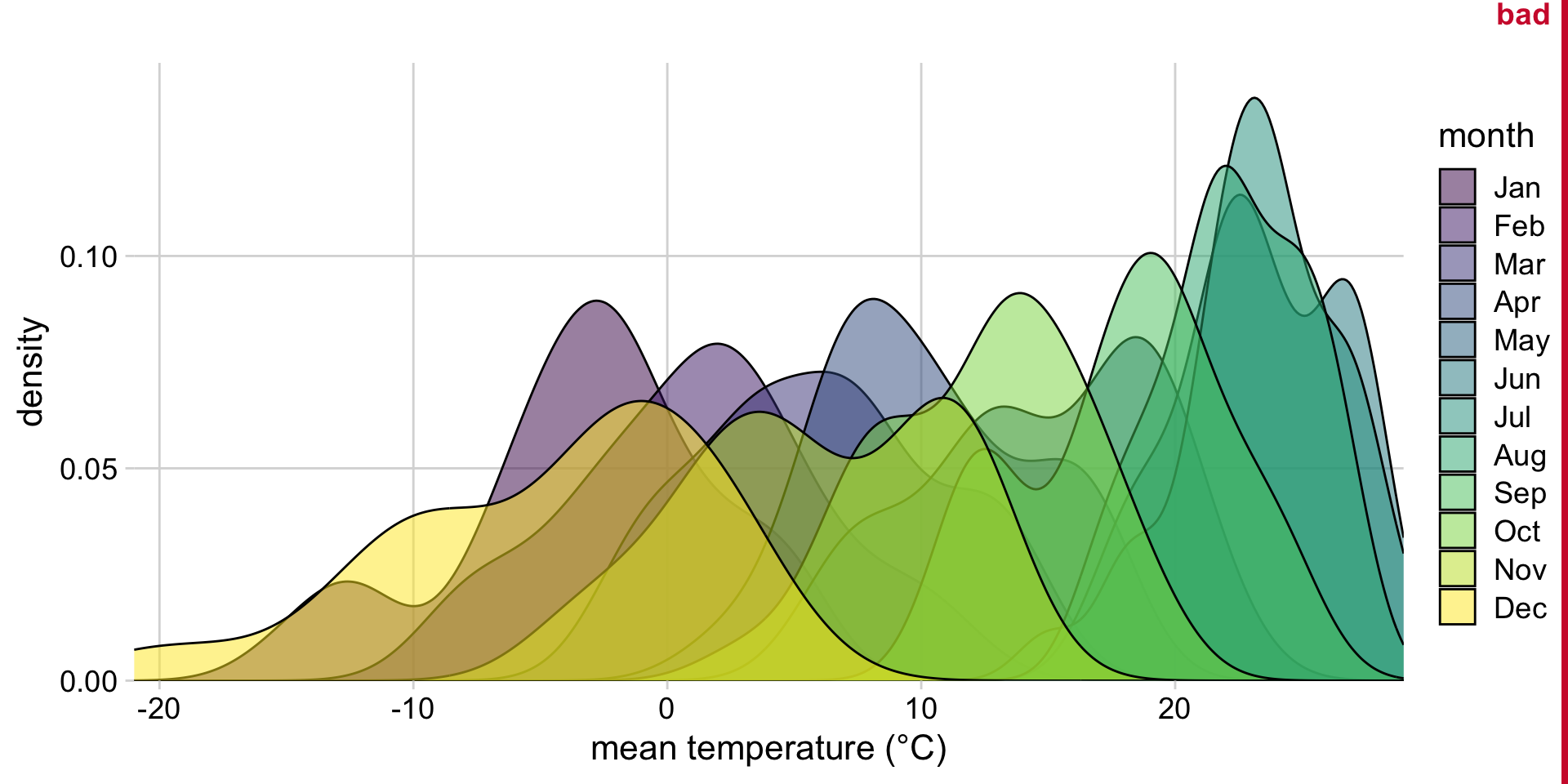
A bad idea: Many overlapping density plots
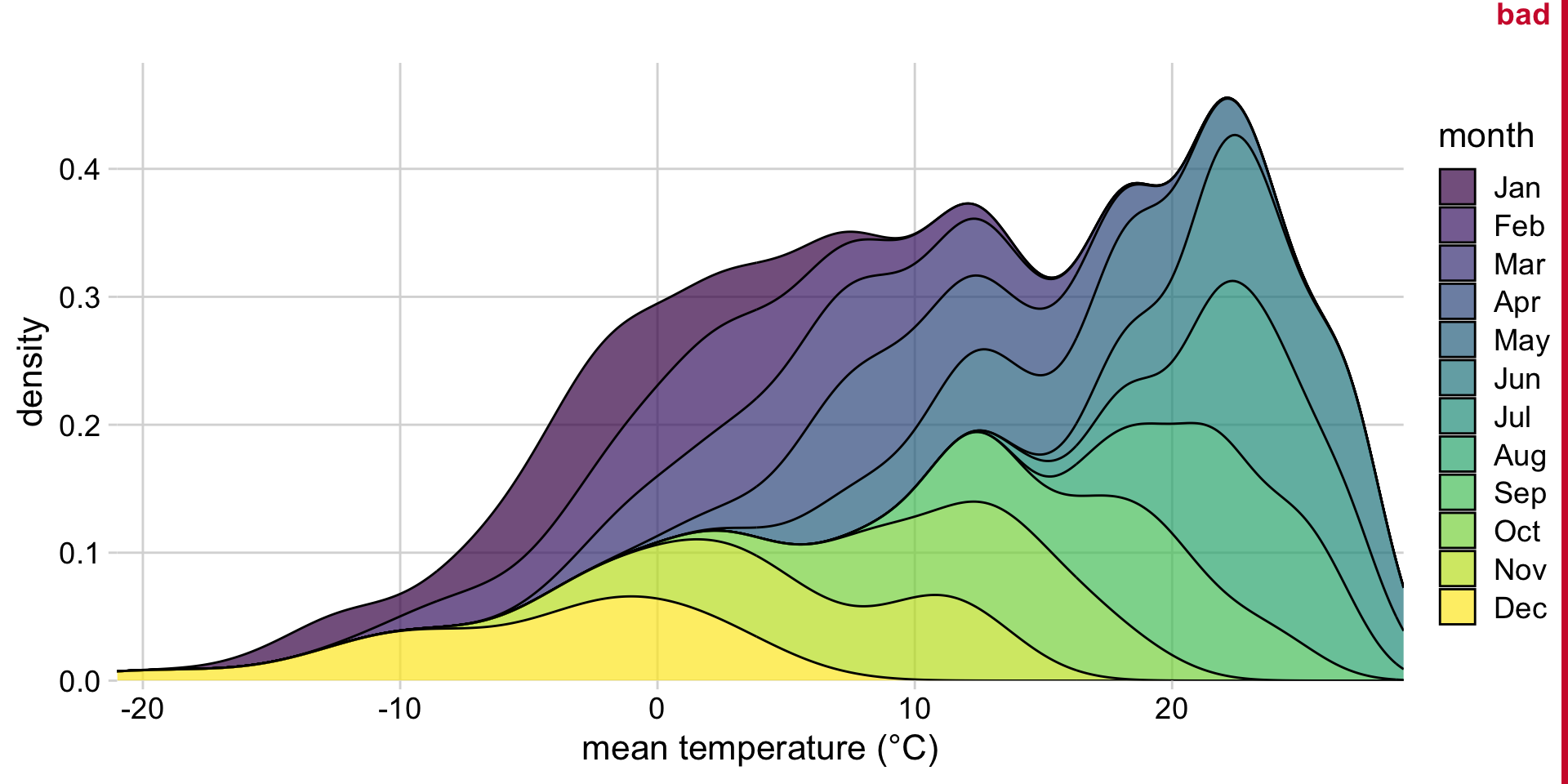
Another bad idea: Stacked density plots
Somewhat better: Small multiples
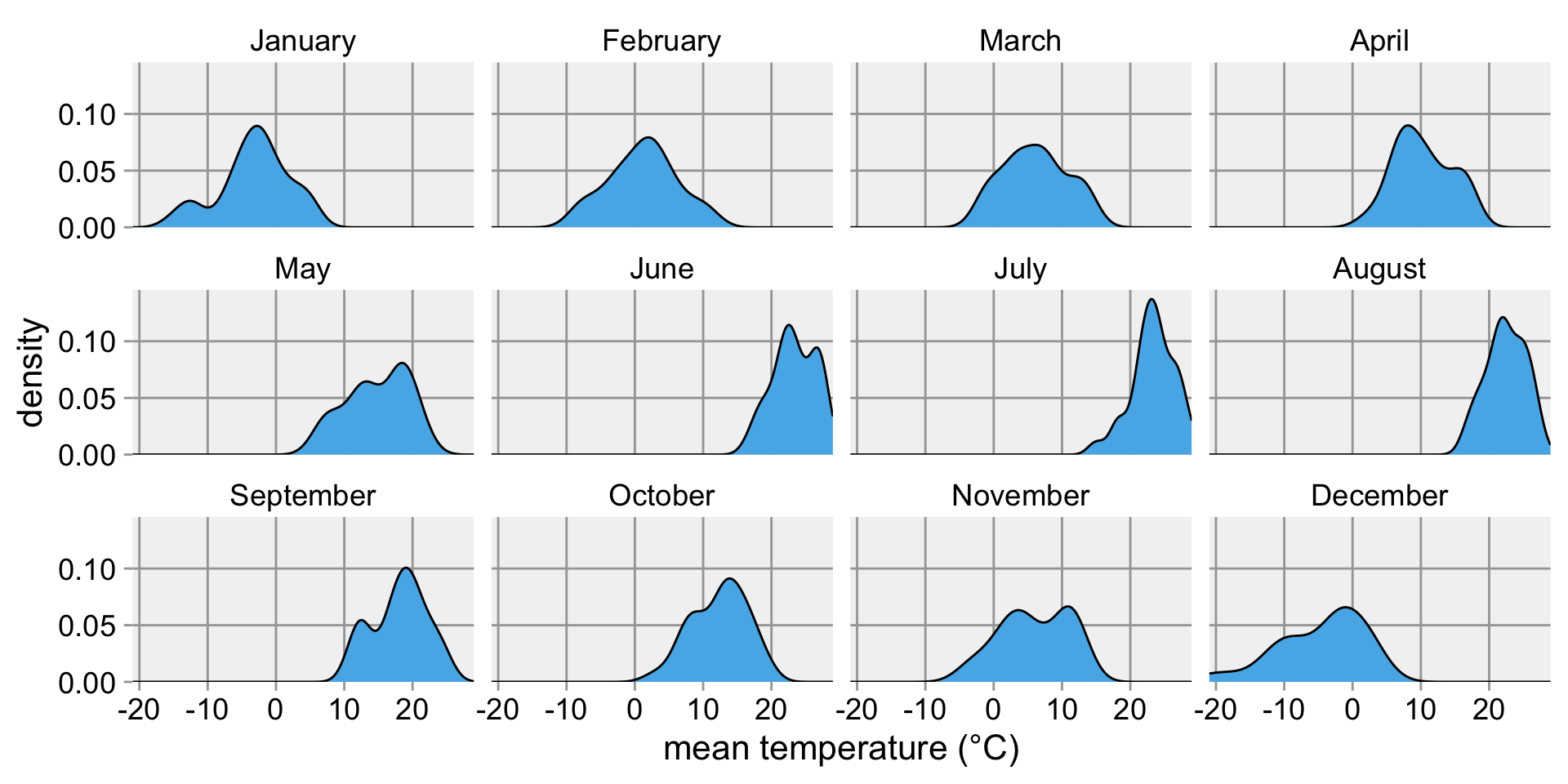
Instead: Show values along y, conditions along x
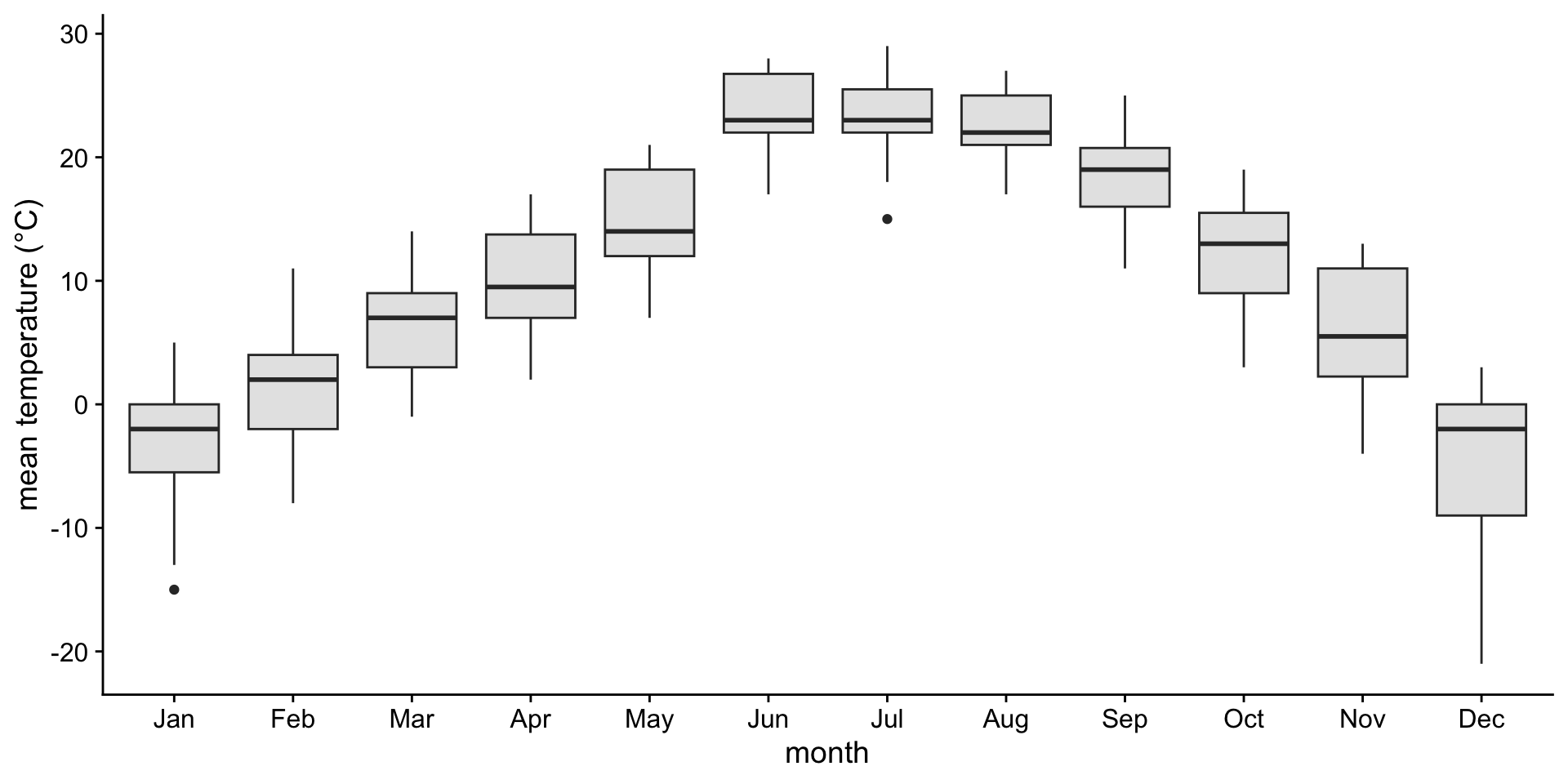
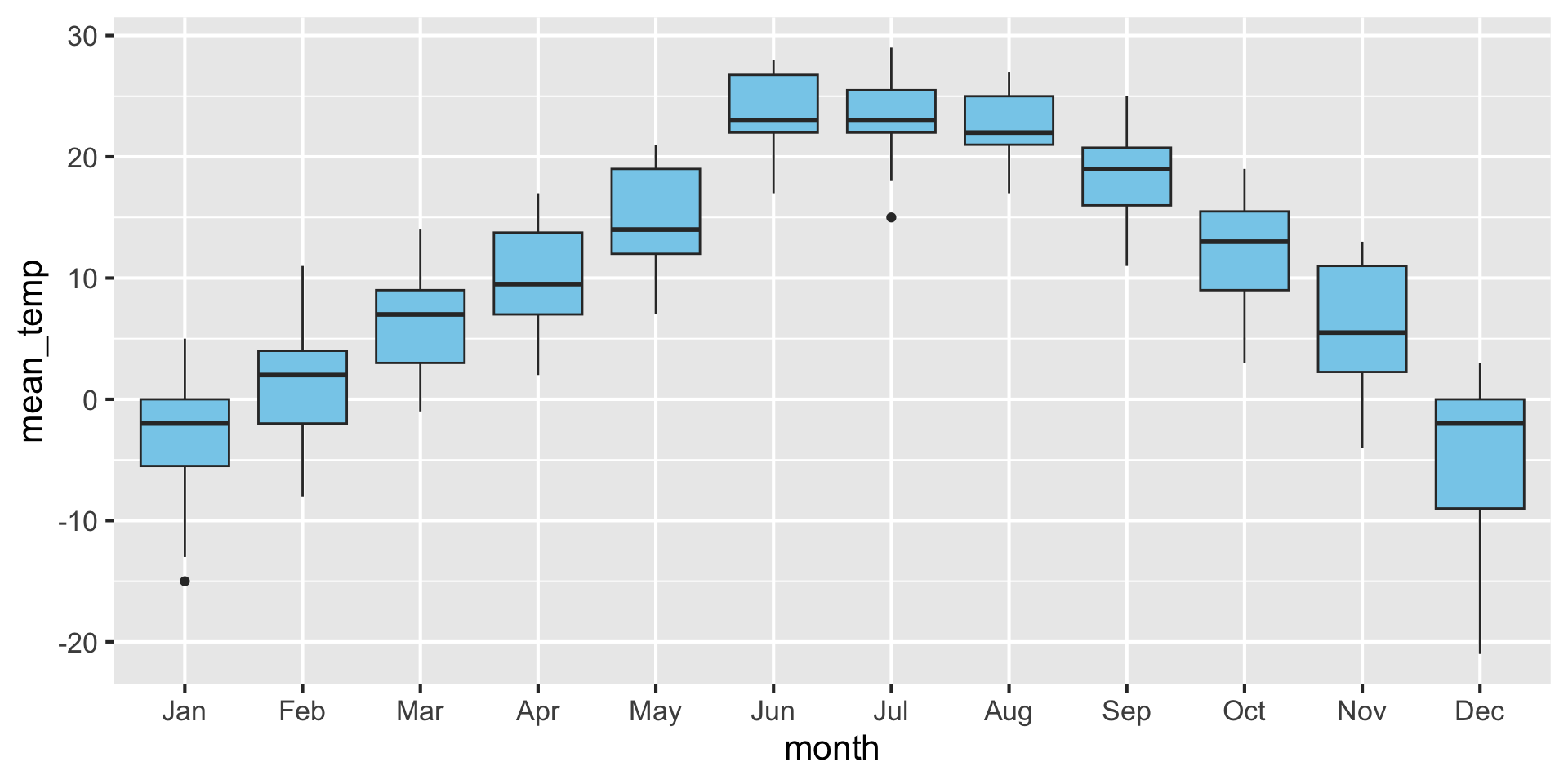
A boxplot is a crude way of visualizing a distribution.
How to read a boxplot

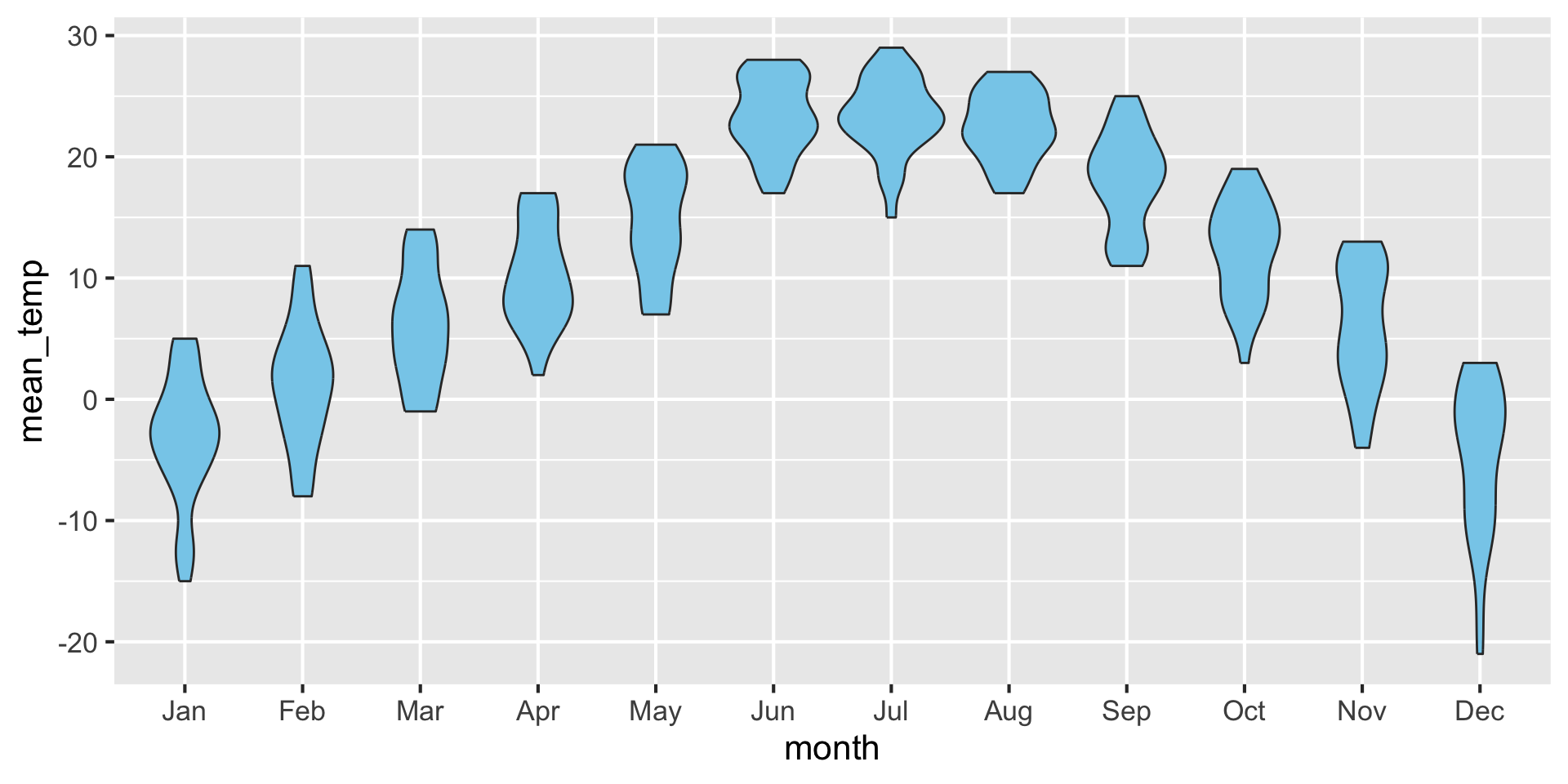
If you like density plots, consider violins
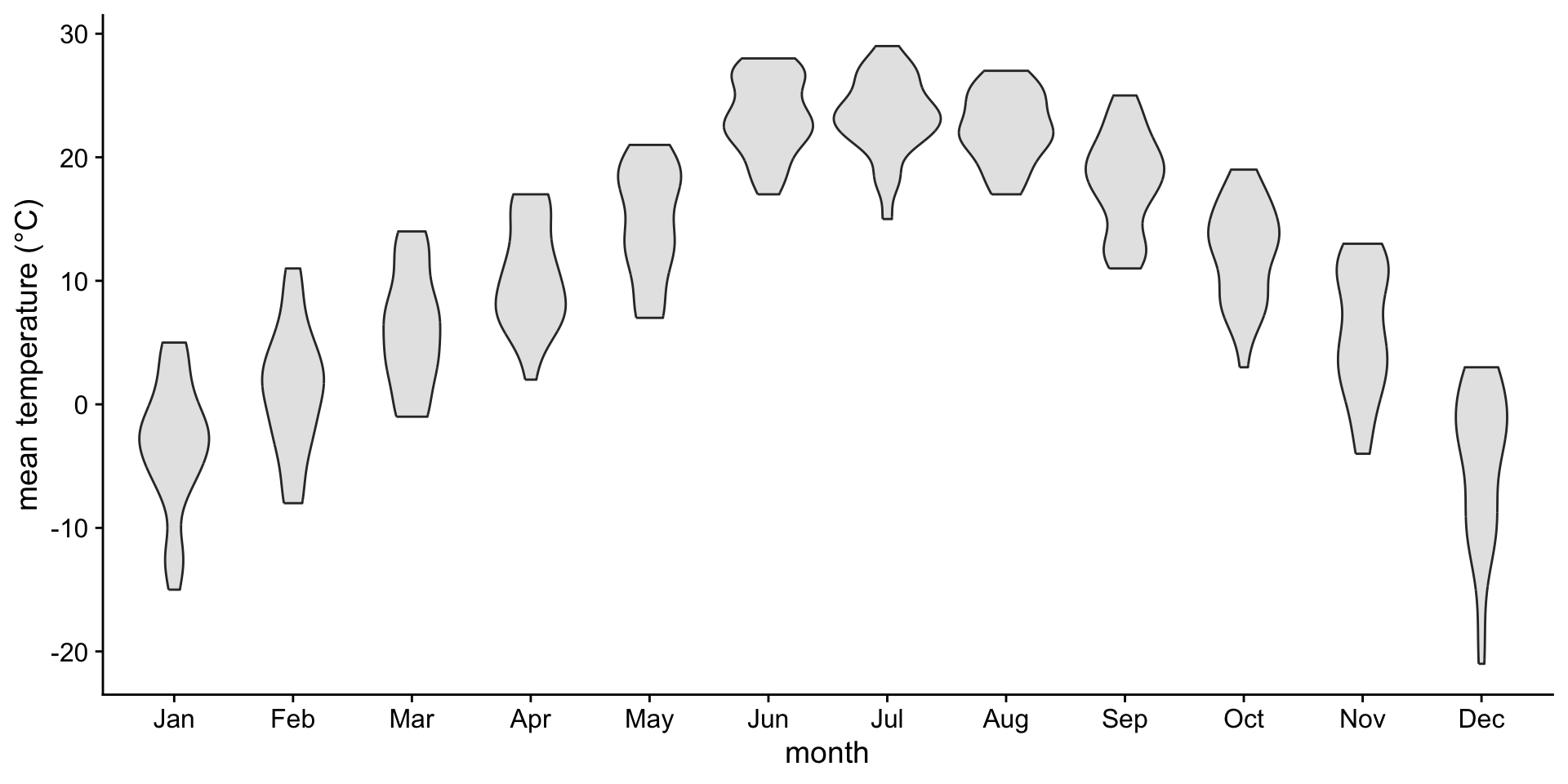
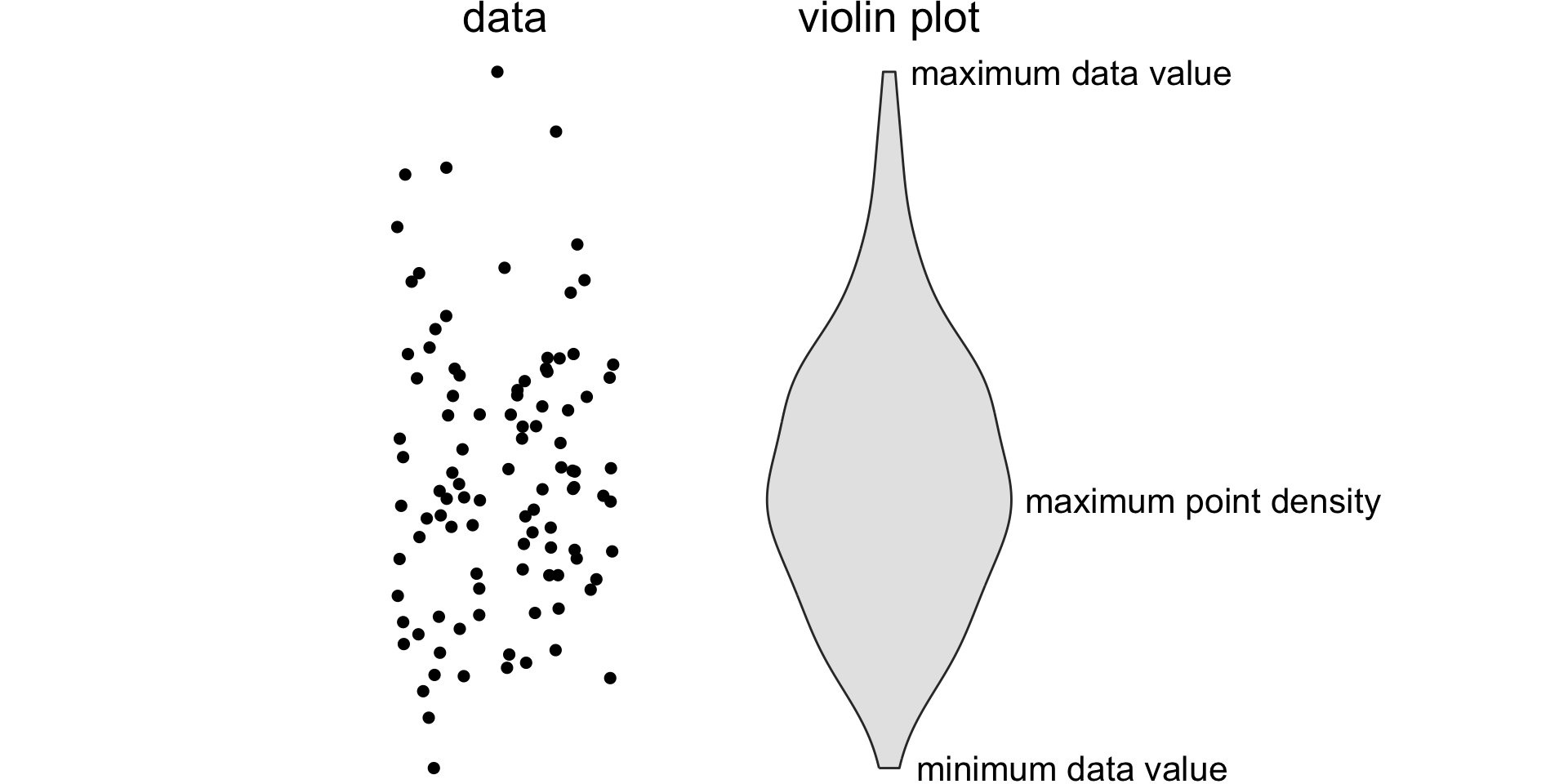
A violin plot is a density plot rotated 90 degrees and then mirrored.
How to read a violin plot
For small datasets, you can also use a strip chart
Advantage: Can see raw data points instead of abstract representation.
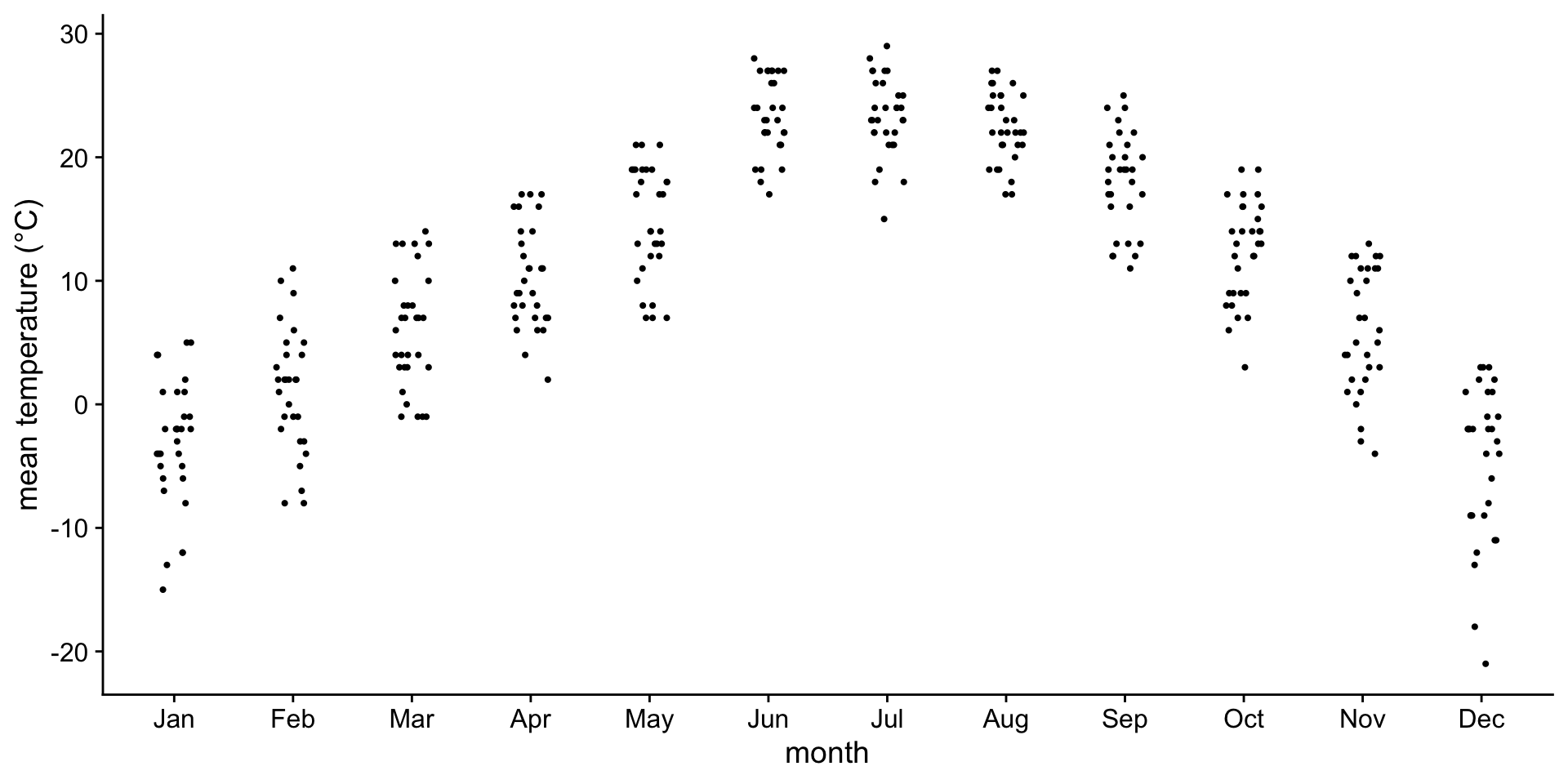
Horizontal jittering may be necessary to avoid overlapping points.
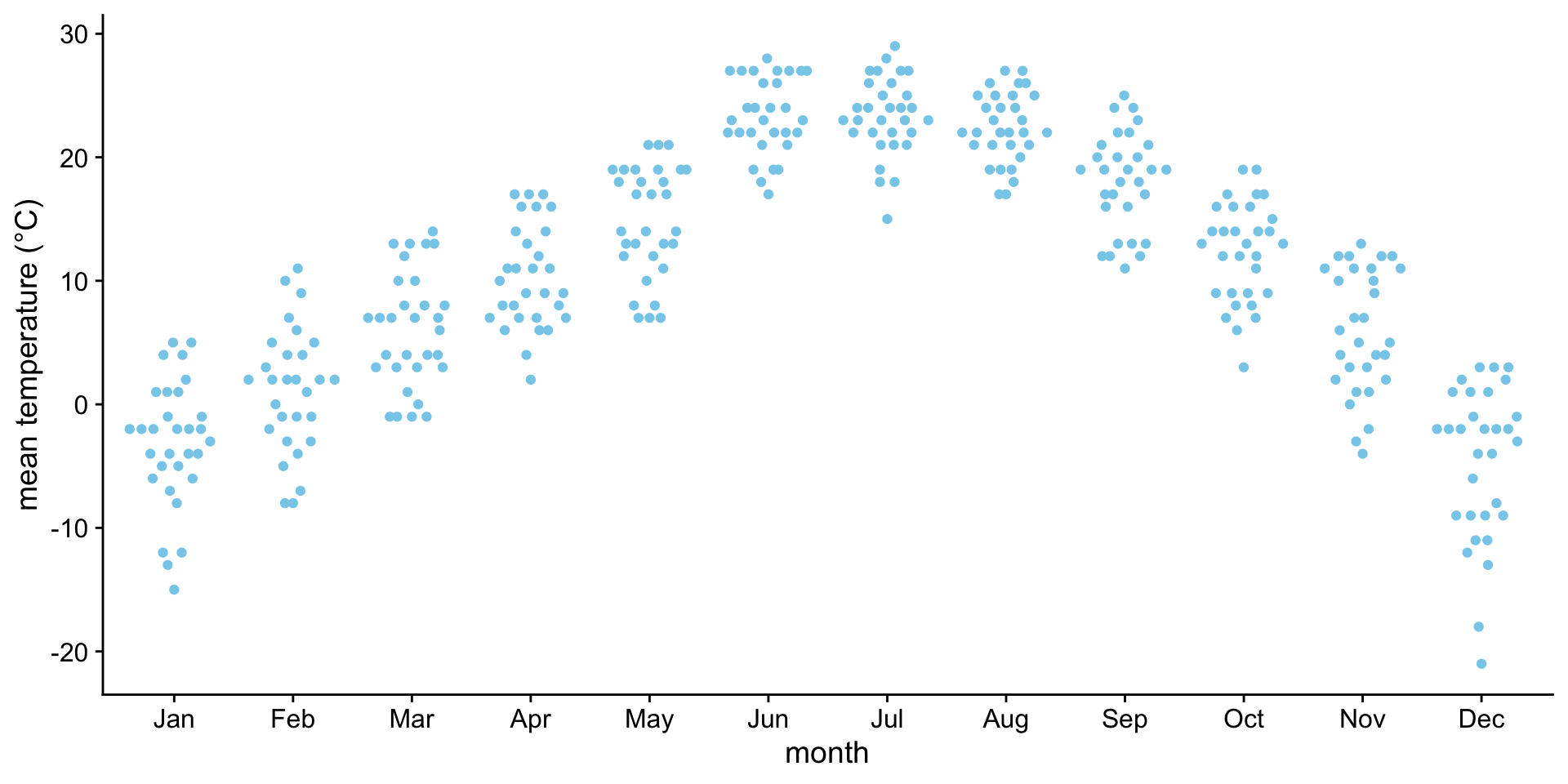
Another option is a scatter-density plot
Advantage: Best of both worlds for violin and jitter plot, see the raw data but also see the shape of the density
Examples: Boxplot {auto-animate: true}
Examples: Violins {auto-animate: true}
Examples: Strip chart (no jitter) {auto-animate: true}
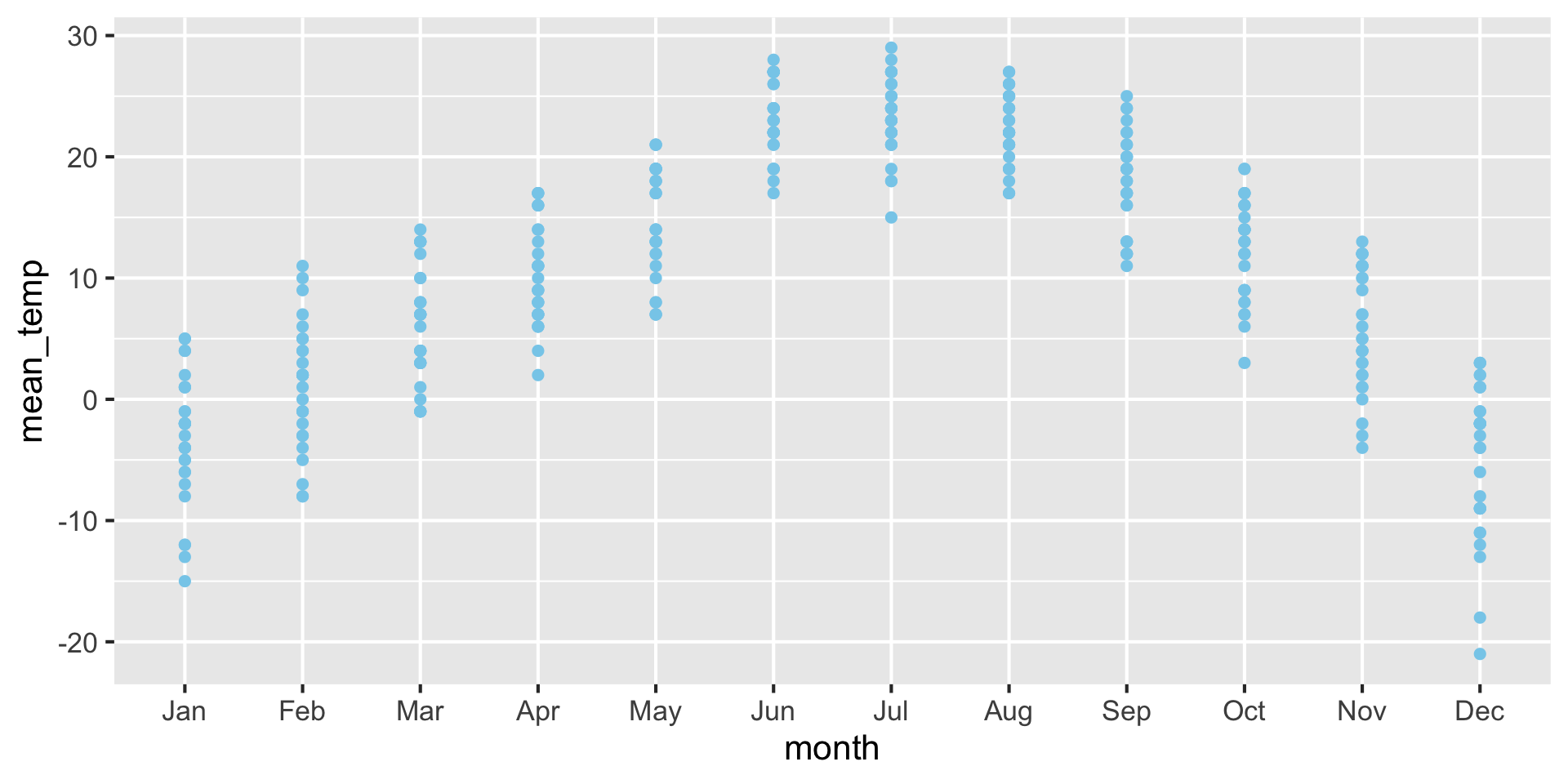
Examples: Strip chart (w/ jitter) {auto-animate: true}
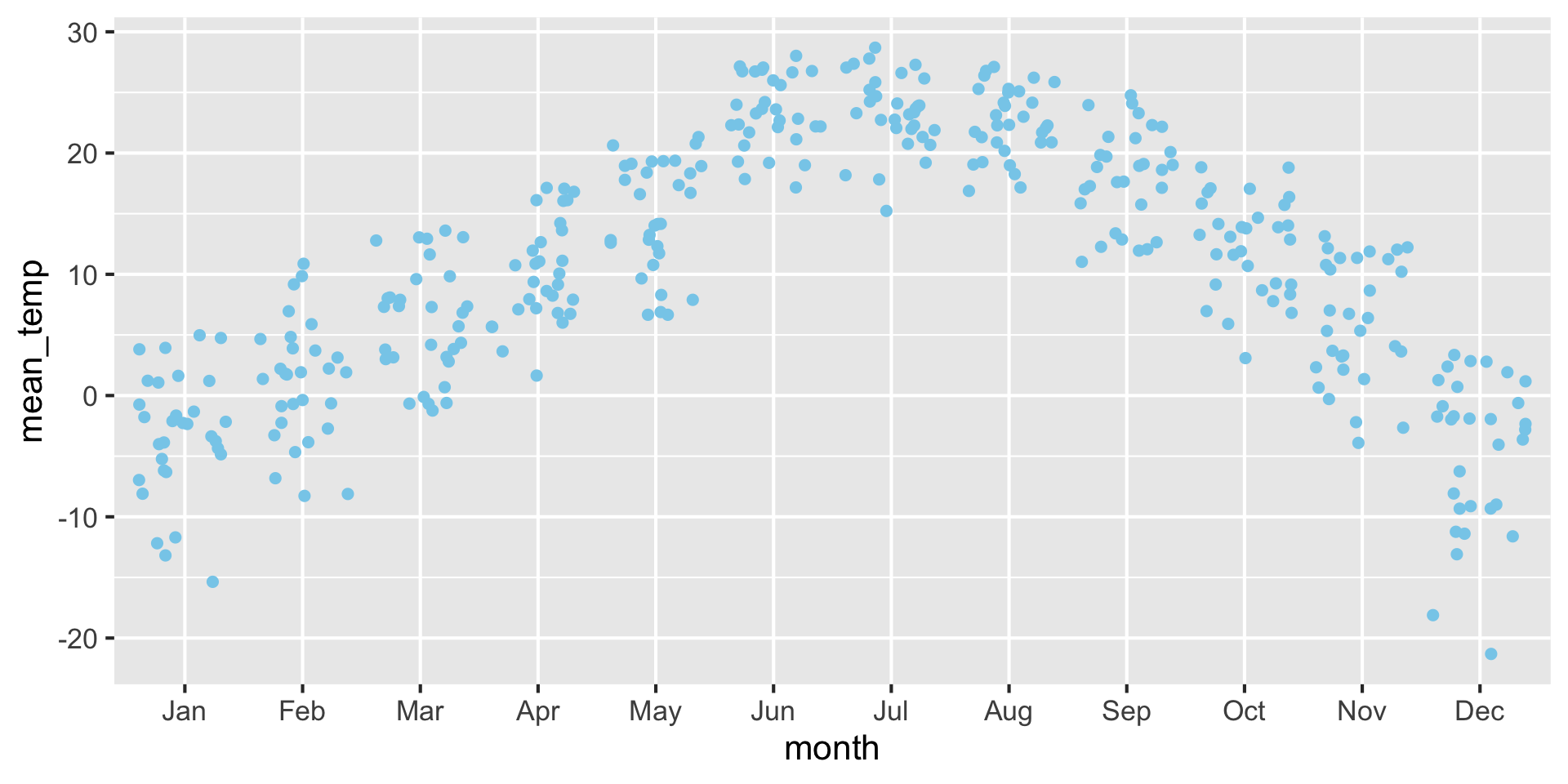
Examples: Scatter density plot {auto-animate: true}